ครั้งนี้มาลองทำ Market Basket Analysis (MBA) เป็นเทคนิคที่สำคัญสำหรับ Data Analyst ในการค้นหาความสัมพันธ์ของสินค้าเพื่อวางแผนโปรโมชั่นขายแพ็คคู่ 🛍️ หรืออื่นๆ ในทำนองเดียวกัน เช่น การจัดชั้นวางของในห้างสรรพสินค้า ว่าจะวางอะไรไว้ใกล้กับอะไรดี, หรือใน online shopping อาจจะใช้ในเรื่องการแนะนำสินค้าอะไรต่อไปให้ลูกค้าดี
และหัวใจหลักของ MBA คือการค้นหา กฎ ที่อยู่ในรูปแบบ A→B ซึ่งหมายความว่า “ถ้าลูกค้าซื้อสินค้า A แล้ว (Antecedent) ลูกค้ามีแนวโน้มที่จะซื้อสินค้า B ด้วย (Consequent)”
ในภาษา R (ครั้งนี้) เราจะใช้แพ็กเกจ arules และอัลกอริทึม Apriori เป็นหลัก โดยเริ่มจาก transaction เลย ว่าเริ่มจัดการยังไง คำนวณผลลัพธ์ยังไง และจบยังไง.
การเตรียมข้อมูล (Data Preparation)
มาดูหน้าตาของตาราง transaction การขายสินค้าในแต่ละวันกันก่อน ซึ่งมีหลากลายรูปแบบเลยในการเก็บข้อมูลของแต่ละร้าน แต่สิ่งที่เราจะเอามาใช้วิเคราะห์ MBA ในครั้งนี้ ที่จำเป็นจริงๆ คือ
- รหัส(คอลัมน์)ที่บอกว่า นี่การซื้อ 1 ครั้ง หรือ 1 ตะกร้า ที่บอกว่าสินค้าพวกนี้เป็นการซื้อในตะกร้าเดียวกัน
- ชื่อสินค้า เพื่อให้ง่ายต่อการอ่าน/ตีความผลลัพธ์
ซึ่งในฐานข้อมูลเราอาจจะเก็บ timestamp วันที่ที่ซื้อ รหัสแคชเชียร์ จำนวนขาย ราคาต่อหน่วย หน่วยนับ บลาๆ แต่เราจะตัดมาเฉพาะที่จะใช้ก็พอครับ
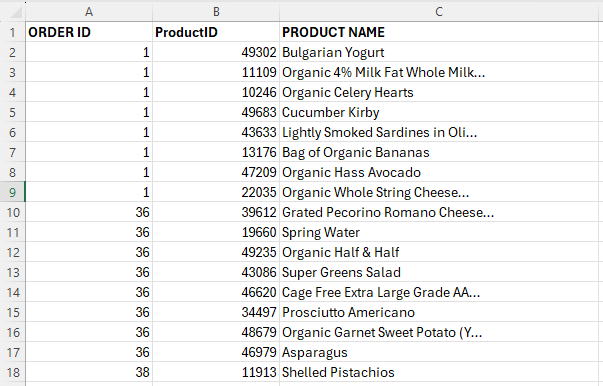
จากในรูป order_id หนึ่งหมายเลข หมายถึง 1 ตะกร้า ที่ประกอบด้วยสินค้า (product_name) หรือ SKU หลายๆ อย่างที่ลูกค้าหยิบลงตะกร้าแล้วจ่ายเงิน
ในภาษา R เราจะใช้แพ็กเกจ arules และอัลกอริทึม Apriori เป็นหลักครับ เริ่มเลอ…
#### Load library & data ####
library(tidyverse)
library(stringr)
library(arules)ทำการอ่านไฟล์ข้อมูลที่เราเตรียมมา หรือไฟล์ที่เราได้ทำการอ้อนวอนต่อ data engineer 🙏 ให้เตรียมให้หน่อยย
df_ <- read_csv('RefFiles/ItemsPurchase-2.csv')
df_ <- data.frame(df_)
df_ %>% head(5)
เข้าสู่ขั้น EDA นิดนึงเนอะ เพียงแค่จะดูว่าไฟล์มีขนาดกี่แถว กี่คอลัมน์ มีค่าว่างหรือเปล่า?
#### eda ####
summary(df_)
str(df_)
โดยฟังก์ชัน summary() ก็จะบอกขนาดของค่าว่าง (NA) ให้ด้วย (ถ้ามี) แบบรูปข้างบนเลย, ฟังก์ชัน str() ก็จะดูโครงสร้างของข้อมูล บอกว่าเป็นชนิดไหน มี 1,048,575 แถว (observations) และมี 3 คอลัมน์ (variables)
จากตัวอย่างที่แอดแสดงข้างบนจะเห็นว่าหัวคอลัมน์ มันขัดใจนิดนึง ขอตัดเข้าพาร์ท transform แก้ตารางกับปรับ type ก่อนครับ
# list columns
colnames(df_) <- tolower(colnames(df_))
# rename columns
names(df_)[1] <- 'order_id'
names(df_)[3] <- 'product_name'
colnames(df_)
# convert type
df <- df_ %>%
select( order_id, product_name ) %>%
mutate( order_id = as.character(order_id) )
summary(df)เริ่มจากการปรับหัวคอลัมน์เป็นตัวพิมพ์เล็ก tolower(), เปลี่ยนชื่อคอลัมน์, สุดท้ายมาเลือกเฉพาะคอลัมน์ที่ต้องการ select(), และแปลงชนิดข้อมูล mutate() ทั้งหมดเก็บในตัวแปรใหม่ชื่อ df แล้ว summary() ออกมาดูอีกครั้ง

เข้าสู่ session: Data preparation เป็นการรวมสินค้าแต่ละตะกร้า (order_id) หรือใบเสร็จเดียวกัน ให้อยู่ใน 1 แถว โดยใช้ตัวคั่นเป็น comma จะได้ผลลัพธ์แบบนี้เลย
#### data preparation ####
# การรวมรายการสินค้าในแต่ละ Invoice/Order ID
trans_df <- df %>%
filter( !is.na(product_name) ) %>%
group_by( order_id ) %>%
summarise(
items = str_c(product_name, collapse = ',')
)
sample_n(trans_df, 5)- ใช้ order_id เป็นตัวระบุการทำรายการ (Transaction)
- ใช้ product_name เป็นรายการสินค้า

จากนั้นก็มาแปลงให้เป็นรูปแบบ Transactions: โดย arules ต้องการไฟล์ในรูปแบบ transaction (เหมือนกับไฟล์ csv ที่แต่ละแถวคือหนึ่งตะกร้าสินค้า) เราจะบันทึก ‘transaction_data’ ที่รวมสินค้าแล้วออกมาเป็นไฟล์ชั่วคราวแล้วอ่านกลับเข้าไปใหม่ เก็บไว้ที่ตัวแปร trans
# แปลงเป็นรูปแบบ Transactions
url_file <-"RefFiles/trans.csv"
write.csv(trans_df$items, url_file, quote = F, row.names = F)
trans <- read.transactions(url_file, format = "basket", sep = ",", skip = 1)
# ตรวจสอบข้อมูลเบื้องต้น
inspect(head(trans))
itemFrequencyPlot(trans, topN = 10) # สินค้าในตะกร้าที่ซื้อบ่อยลองตรวจสอบข้อมูลเบื้องต้นนิดนึงหลังจากอ่านไฟล์เข้ามา คำสั่ง inspect() คือสำรวจดูว่าแต่ละตะกร้ามีสินค้าอะไรบ้าง และลงพล็อตกราฟสินค้าที่ถูกซื้อบ่อยที่สุด 10 อันดับออกมา

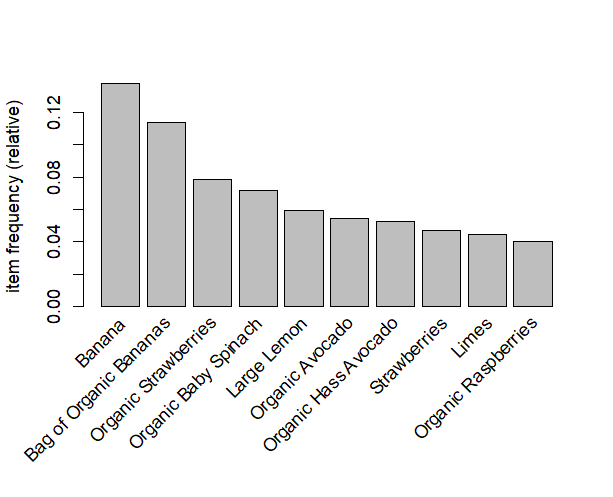
คร่าวๆ เราจะเห็นว่า 🍌 Banana ขายดีเวอร์ สินค้าส่วนใหญ่เป็นอาหารสดกลุ่มผักผลไม้ นั่นเอง
การสร้าง Association Rules ด้วย Apriori
เราจะหากฎความสัมพันธ์โดยใช้ฟังก์ชัน apriori() เน้นการค้นหากฎที่มีสินค้าเพียง 2 ชิ้น (A => B หรือ B => A) ซึ่งหมายถึงการซื้อสินค้าคู่กันเพื่อตอบโจทย์การ “ขายคู่” ที่เราตั้งไว้ด้านบน
โดยเราต้องตั้งกฏประมาณนี้:
- ค้นหากฎที่มีสินค้าเพียง 2 ชิ้น (A => B หรือ B => A) ซึ่งหมายถึงการซื้อสินค้าคู่กัน
- supp (Support): กำหนดความถี่ขั้นต่ำ (เช่น 0.005 = 0.5% ของรายการทั้งหมด)
- conf (Confidence): กำหนดความมั่นใจขั้นต่ำ (เช่น 0.3 = 30%)
- maxlen: กำหนดจำนวนสินค้าสูงสุดในกฎ (maxlen=2 เพื่อให้ได้กฎแบบ “คู่”)
ซึ่งเดี๋ยว Support, Confidence จะอธิบายต่อ (หัวข้อ: ตัววัดประสิทธิภาพ Matrics) ด้านล่างครับ ใจเย็นๆ
#### การสร้าง Association Rules ด้วย Apriori ###
rules <- apriori(trans,
parameter = list(supp = 0.005, conf = 0.3, maxlen = 2),
control = list(verbose = FALSE))อาจต้องลองปรับค่า ‘supp’ (Support), ‘conf’ (Confidence) ให้เหมาะสมกับขนาดข้อมูลของเรา หากได้กฎน้อยไป ให้ลดค่า, หากได้กฎเยอะไป ให้เพิ่มค่าดูได้ครับ
การค้นหาคู่สินค้าที่ดีที่สุด
เนื่องจากเราต้องการหา “คู่สินค้า” ที่มีการซื้อมากที่สุด เพื่อจัดโปรโมชั่นขายแพ็คคู่ จึงควรให้ความสำคัญกับ Support และ Lift ที่สูง
- Support สูง: แสดงว่าเป็นคู่ที่ถูกซื้อบ่อยมากที่สุด
- Lift สูง: แสดงว่าเป็นคู่ที่มีความสัมพันธ์กัน “เป็นพิเศษ” (ไม่ใช่แค่เป็นสินค้าขายดีทั่วไป)
มาอีกแล้วคำศัพท์ อธิบายด้านล่าง (หัวข้อ: ตัววัดประสิทธิภาพ Matrics) ครับ
#### การค้นหาคู่สินค้าที่ดีที่สุด ####
# จัดเรียงกฎตาม Lift สูงสุด และ Support สูงสุด
rules_sorted <- sort(rules, by = c("lift", "support"), decreasing = TRUE)
# กรองเฉพาะกฎที่มี Support และ Lift สูงๆ (อาจจะเลือก Top N)
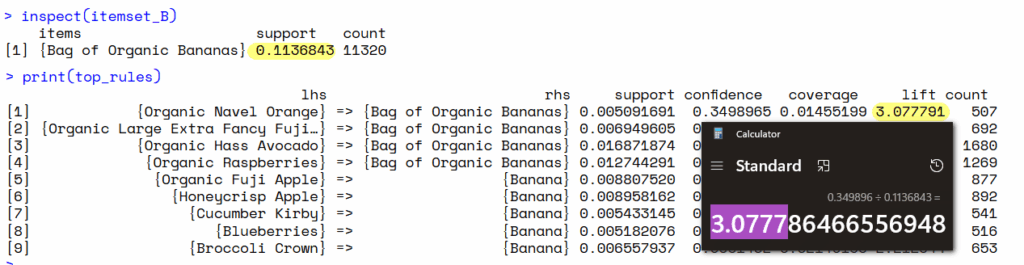
top_rules <- inspect(head(rules_sorted, n = 10))
print(top_rules)กฎที่ได้จะอยู่ในรูปแบบ {สินค้า A} => {สินค้า B} ซึ่งสินค้าคู่ที่น่าสนใจที่สุดคือสินค้าที่อยู่ใน 10 อันดับแรก โดยพิจารณาจาก:
- Lift: ควรมีค่า > 1 มากๆ (ยิ่งสูงยิ่งดี)
- Support: ควรมีค่าสูงพอสมควร (ความถี่ที่เกิดขึ้นจริง)
- Confidence: ควรมีค่าสูง (ถ้าซื้อ A โอกาสซื้อ B ก็สูง)

การตีความของคู่สินค้าอันดับแรก Organic Navel Orange 🍊(ส้มไร้เมล็ด) กับ Bag of Organic Bananas 🍌(กล้วยออแกนิค): ถ้าผลลัพธ์ออกมาเช่นนี้ หมายความว่า:
- คู่สินค้า Organic Navel Orange (ส้มไร้เมล็ด) และ Bag of Organic Bananas (กล้วยออแกนิค) ถูกซื้อร่วมกันใน 0.5% ของรายการทั้งหมด — จาก Support 0.005091639
- คนที่ซื้อ Organic Navel Orange (ส้มไร้เมล็ด) มีโอกาส 35% ที่จะซื้อ Bag of Organic Bananas (กล้วยออแกนิค) — จาก Confidence 0.3498965
- การซื้อ Organic Navel Orange (ส้มไร้เมล็ด) เพิ่มโอกาสซื้อ Bag of Organic Bananas (กล้วยออแกนิค) ถึง 3 เท่า เมื่อเทียบกับการซื้อ Bag of Organic Bananas (กล้วยออแกนิค) ทั่วๆ ไป — จาก Lift 3.077822
🌵 คู่สินค้าที่มี Lift สูง, Support สูงพอสมควร คือคู่ที่เราควรนำไปจัดโปรโมชั่น “ซื้อคู่” ครับ 👍
ครั้งนี้แอดหา data sample อยู่นานมาก กว่าจะได้มาโค้ด หลักๆ คือสินค้าที่เขา mockup ไว้ใน Kaggle แอดอธิบายไม่ได้ว่ามันคืออะไร แฮะๆ จนมาจบที่ข้อมูลชุดนี้ หวังว่าคุณผู้อ่านที่แวะแมา จะทำความเข้าใจไปพร้อมๆ กับแอดนะครับ
[Optional] ตัววัดประสิทธิภาพ (Metrics)
Support
โดย Support (ความถี่หรือความบ่อย) 🛒 สัดส่วนของรายการซื้อสินค้า A และ B (คู่กัน) ต่อจำนวนรายการซื้อทั้งหมด นั่นคือมันวัดความถี่ในการปรากฏร่วมกันของสินค้า A และ B ในชุดข้อมูลของเราครับ

เนื่องจากค่า support จะเกิดขึ้นในทุกคู่สินค้า (A→B) ตามความถี่ของการซื้อสินค้า จึงต้องกำหนดขั้นต่ำ Minimum Support ที่เราสนใจ เพราะหากค่า support ยิ่งเยอะขึ้น เราก็จะยิ่งมั่นใจว่าจะเกิดเหตุการณ์ซื้อแบบเดียวกันนี้บ่อยขึ้น
จึงต้องมีการตั้ง Minimum Support ช่วยให้เรา กรองกฎที่เกิดขึ้นน้อยครั้ง ซึ่งมักเป็นสัญญาณรบกวน (Noise) ออกไป (จากที่เราใส่ parameter = list(supp = 0.005) ในกฏนั่นเอง) และเน้นเฉพาะ ชุดสินค้าที่ถูกซื้อร่วมกันบ่อย จนเป็นที่น่าสนใจในทางธุรกิจ
ที่นี้ R คำนวณตัวเลขยังไง ก่อนที่มันจะคำนวนมาให้เรา
# [optional]
# หาจำนวนรายการซื้อทั้งหมด
length(trans_df$order_id)
# สร้างรายการสินค้าตามความถี่ทั้งหมด และดึงเฉพาะ supp >= 0.005
frequent_itemsets <- apriori(trans,
parameter = list(supp = 0.005, target = "frequent itemsets"))
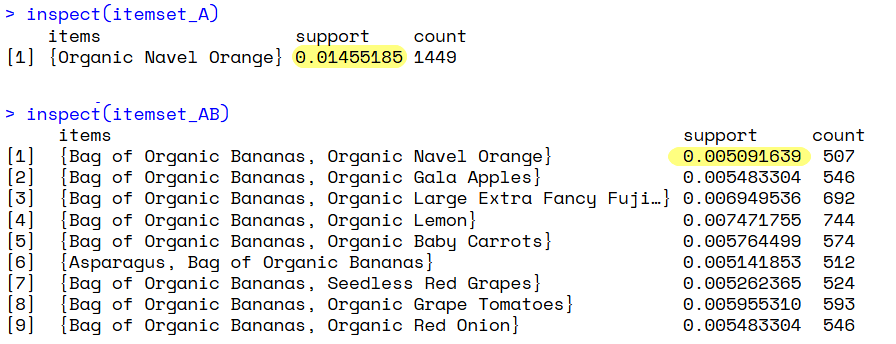
# กรองหา Itemset ที่ประกอบด้วย (A) และ (B) assume ว่าเราจะคำนวณ 2 ไอเทมนี้
a <- "Organic Navel Orange"
b <- "Bag of Organic Bananas"
itemset_AB <- subset(frequent_itemsets, items %in% c( a, b ) & size(items) == 2)
# ดูผลลัพธ์: จะได้ Support Count(A U B) + แล้วมองหารายการที่สนใจ
inspect(itemset_AB)
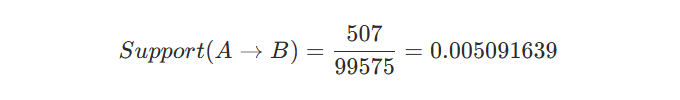
Confidence
ทีนี้แค่ Support อย่างเดียวอาจยังไม่พอ เพราะเราต้องการทราบว่า “ในบรรดาลูกค้าที่ซื้อ A ทั้งหมด มีกี่เปอร์เซ็นต์ที่ซื้อ B ตามมาด้วย?” และสิ่งนี้คือ Confidence (ความเชื่อมั่น) จะเข้ามาตอบโจทย์นี้ครับ
Confidence คือการวัดความน่าจะเป็นที่จะเกิดเหตุการณ์ B เมื่อรู้ว่าเหตุการณ์ A เกิดขึ้นแล้ว (กฎ A→B) มีความน่าเชื่อถือแค่ไหน จากสูตร
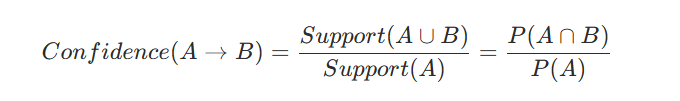
ที่นี้ R คำนวนยังไงกัน
# หลังจากคำนวน frequent_itemsets แล้ว
a <- "Organic Navel Orange"
b <- "Bag of Organic Bananas"
itemset_AB <- subset(frequent_itemsets, items %in% c( a, b ) & size(items) == 2
inspect(itemset_AB)
# กรองหา Itemset ที่ประกอบด้วย a และมีขนาดเท่ากับ 1
itemset_A <- subset(frequent_itemsets, items %in% c( a ) & size(items) == 1)
inspect(itemset_A) 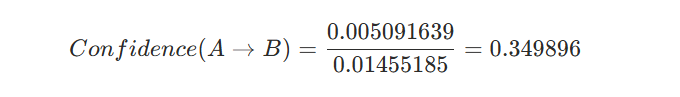
แม้ค่า Support และ Confidence ของกฎ A→B นั้นมี ข้อจำกัด อยู่บ้าง เพียงแค่ว่าการซื้อ A แล้วจะมีการซื้อ B ต่อ แต่แล้วเราจะรู้ได้อย่างไรว่ามีความมันมีความสัมพันธ์กันจริงๆ ไม่ใช่เหตุการณ์สินค้านั้นลดราคาพร้อมกันแล้วเกิดการซื้อขึ้น สถิติตัวสุดท้ายที่เข้ามาแก้ไขปัญหานี้คือ Lift
ข้อจำกัดของ Confidence คือมันอาจสูงได้เพียงเพราะสินค้า B (เช่น นม หรือไข่) ถูกซื้อบ่อยมากอยู่แล้ว โดยไม่เกี่ยวกับว่าลูกค้าซื้อ A หรือไม่เลย นั่นคือเราวัดโดยไม่ได้เทียบกับ ความถี่พื้นฐาน ของสินค้า B
เราจึงต้องมีการแยกแยะระหว่าง ความสัมพันธ์ที่แท้จริง (Association) กับ เหตุการณ์บังเอิญ (Coincidence)
Lift
Lift คือการวัดว่าโอกาสที่ลูกค้าจะซื้อ B เพิ่มขึ้น กี่เท่า เมื่อลูกค้ารู้ว่าซื้อ A ไปแล้ว โดยเทียบกับโอกาสที่ลูกค้าจะซื้อ B อยู่แล้วตามปกติ (Baseline Probability) โดย Lift จะวัดว่ากฎ A→B มีความแข็งแกร่งและน่าสนใจ เกินกว่าการเกิดร่วมกันแบบสุ่ม หรือไม่
ซึ่งมีสูตรคำนวณคือ
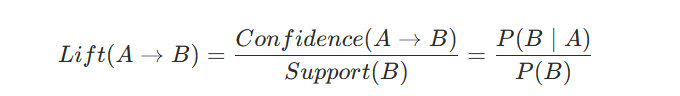
โดยทั่วไป Lift ที่สูง (สูงกว่า 1) คือสิ่งที่เรามองหา แต่มาลองดูความหมายอื่นด้วยนะครับ
| ค่า Lift | การตีความ (ความสัมพันธ์) | ความหมาย |
| เท่ากับ 1 | เป็นอิสระต่อกัน (Independent) | การซื้อ A ไม่ได้มีผลต่อโอกาสในการซื้อ B กฎไม่มีความน่าสนใจ |
| มากกว่า 1 | ความสัมพันธ์เชิงบวก (Positive Association) | การซื้อ A เพิ่ม โอกาสในการซื้อ B อย่างชัดเจน นี่คือ กฎที่แข็งแกร่งและน่าสนใจ |
| น้อยกว่า 1 | ความสัมพันธ์เชิงลบ (Negative Association) | การซื้อ A ลด โอกาสในการซื้อ B สินค้าอาจเป็น สินค้าทดแทนกัน (Substitutes) |
แล้ว R หาค่า lift มาด้วยวิธีการ:
# เราได้หา Confidence(A→B) ไปแล้วก่อนหน้านี้น้า: 0.349896
b <- "Bag of Organic Bananas"
itemset_B <- subset(frequent_itemsets, items %in% c( b ) & size(items) == 1)
inspect(itemset_B)